
Peut-on Entraîner une IA sur ses Données en toute Sécurité ?
Peut-on entraîner une IA sur ses propres données en toute sécurité sans risquer de fuite, de non-conformité ou d’exposition indirecte via le modèle ? En pratique, la réponse est oui, mais uniquement sous conditions strictes. Architecture, gouvernance, tests de fuite et chiffrement déterminent si un projet est maîtrisé ou dangereux. Cet article détaille les risques réels, les techniques éprouvées et les décisions opérationnelles pour entraîner une IA sur des données sensibles tout en gardant le contrôle.
Résumé express
- Oui, mais uniquement dans un environnement isolé, contrôlé et audité
- Les données doivent être minimisées, chiffrées et strictement accessibles
- Le modèle lui-même peut exposer des données (extraction, inversion)
- Des tests de fuite et des exercices de red team sont indispensables
- Gouvernance, traçabilité et contrats complètent la sécurité technique
Pourquoi cette question revient si souvent
Dilemme pragmatique
Les décideurs ne posent pas la question en abstracto. Ils cherchent à valoriser des données sensibles sans générer de risques juridiques ou réputationnels. Ainsi, la formulation « Peut-on entraîner une IA sur ses propres données en toute sécurité » devient un problème pragmatique. Il combine arbitrages entre valeur métier, coûts d’infrastructure et obligations réglementaires. Dans les secteurs fortement régulés, la centralisation seule des données peut déclencher des notifications ou des audits renforcés. Cela influence directement la stratégie d’entraînement.
Maturité organisationnelle
La réponse dépend de la maturité des pratiques internes. Concrètement, il s’agit de classification des données, de cycles de rétention, de politiques de minimisation et de capacités d’audit. Peut-on entraîner une IA sur ses propres données en toute sécurité devient alors une question opérationnelle. Les équipes doivent établir des règles claires : qui prépare les jeux de données, qui lance les expériences, qui valide les modèles avant production. L’effort d’ingénierie requis pour atteindre un niveau de sécurité acceptable peut être substantiel. Il doit donc être budgétisé en amont.
Chaîne d’approvisionnement et facteur humain
Enfin, il ne faut pas négliger le facteur humain et la chaîne d’approvisionnement logicielle. Prestataires, sous-traitants et outils tiers peuvent introduire des vulnérabilités, même si l’entraînement reste « en interne ». La gouvernance du projet doit formaliser les responsabilités et prévoir des revues régulières. Par ailleurs, elle doit inclure des scénarios d’incident. Ainsi, la sécurité devient un continuum plutôt qu’une case à cocher ponctuelle. Les volumes collectés augmentent et les attentes de confidentialité aussi. Les entreprises veulent personnaliser leurs services sans exposer d’informations sensibles. En revanche, les régulateurs et les utilisateurs demandent des garanties. Le risque légal pèse sur chaque projet d’IA. Les décisions techniques influencent l’équilibre entre performance et protection. Plus d’isolation réduit les fuites mais complique l’ingénierie et augmente les coûts. Comprendre ces arbitrages aide à définir une stratégie adaptée aux besoins métier.
Risques principaux

Fuites via le modèle et interfaces exposées
Les risques techniques dépassent la simple fuite de fichiers. Des attaques par extraction permettent d’inférer des exemples d’entraînement à partir d’un modèle accessible. Des techniques comme l’inversion de modèle peuvent reconstruire des éléments sensibles. Ainsi, la question « Peut-on entraîner une IA sur ses propres données en toute sécurité » implique d’évaluer non seulement l’accès aux jeux de données, mais aussi l’accès au modèle et aux interfaces exposées en production. Un modèle accessible sans garde-fous augmente la surface d’attaque.
Biais, qualité des données et impacts opérationnels
Il existe aussi des risques liés aux biais et à la qualité des données. Si ces risques ne sont pas maîtrisés, une fuite peut devenir un problème opérationnel majeur. Fuite d’information et prise de décision erronée se combinent pour accroître l’impact. Par conséquent, il faut intégrer des tests de robustesse, des évaluations de ré-identification et des campagnes de red team. Ces exercices simulent des tentatives d’extraction et mesurent la résilience réelle du modèle.
Mesures et gouvernance opérationnelle
Pour rendre ces évaluations opérantes, il est recommandé d’instituer des métriques de sécurité et des seuils d’acceptation. Ces métriques doivent rejoindre les métriques de performance. Définir des critères clairs permet d’interrompre une expérimentation et d’isoler des jeux de données compromis. Il devient plus facile de lancer des investigations. Ainsi, on réduit la fenêtre d’exposition et on accélère la gestion des incidents. Les risques vont de la fuite accidentelle à l’utilisation malveillante par un attaquant ou par un employé indiscret. Les jeux de données peuvent contenir des identifiants, des secrets commerciaux ou des éléments soumis à des régulations sectorielles. Leur exposition a des conséquences opérationnelles et juridiques. Un autre vecteur critique est le modèle lui‑même : fuites mémorielles, surapprentissage ou sorties restituant des fragments sensibles sont documentés. Les attaques par extraction et les requêtes adversariales permettent à un attaquant d’inférer des éléments d’entraînement s’il obtient un accès au modèle.
Cette approche suppose de ne faire confiance à aucun composant par défaut, y compris aux modèles, aux pipelines et aux utilisateurs internes. Chaque accès doit être explicitement autorisé, limité et journalisé. Cette logique rejoint les principes d’une architecture Zero Trust, où la sécurité repose sur la vérification continue plutôt que sur la confiance implicite.
Quand entraîner une IA sur ses données est réellement sûr (ou non)
C’est généralement acceptable si :
-
Les données sont minimisées et classifiées
-
L’entraînement se fait dans un environnement isolé
-
Les accès au modèle sont restreints et journalisés
-
Des tests d’extraction sont réalisés avant mise en prod
C’est risqué si :
-
Le modèle est exposé via API publique sans filtrage
-
Les données contiennent des identifiants non masqués
-
Aucun test de fuite n’est effectué
-
La gouvernance et la traçabilité sont absentes
Techniques de protection
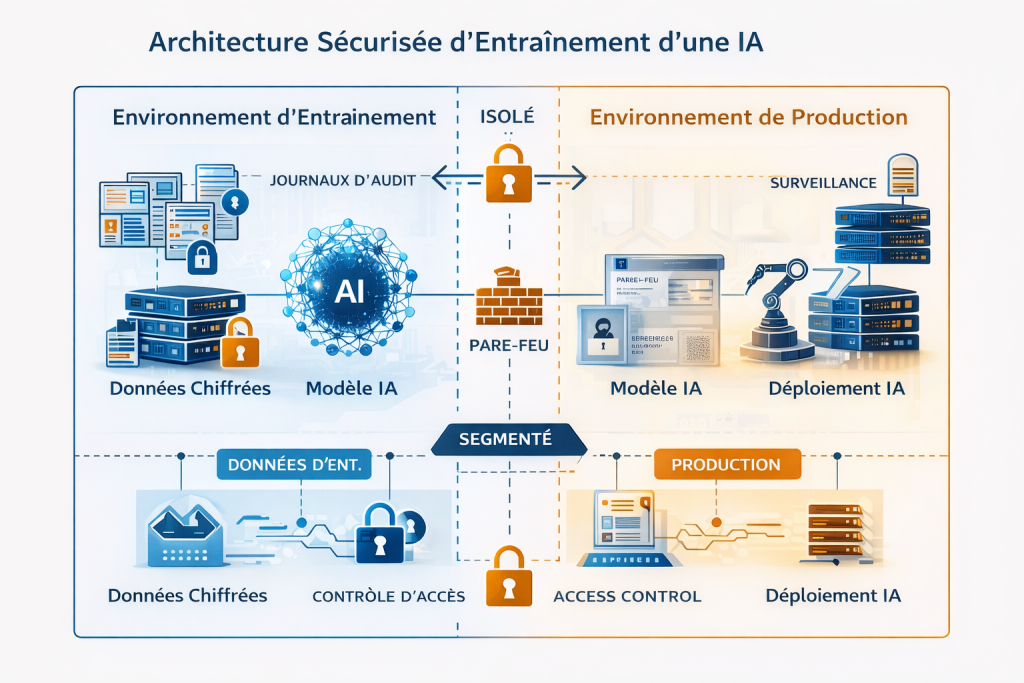
Dans les contextes les plus sensibles, certaines organisations vont plus loin en limitant l’exposition des données dès leur origine. Le recours au chiffrement côté client permet notamment de conserver le contrôle des données avant même leur traitement par l’infrastructure d’entraînement. Cette approche réduit fortement les risques d’accès non autorisé, y compris en cas de compromission partielle de l’environnement.
Tests et validation systématiques

Quand on se demande « Peut-on entraîner une IA sur ses propres données en toute sécurité », la réponse dépend souvent de la capacité à mesurer la fuite potentielle à chaque itération. Il est utile d’intégrer des étapes de test systématiques dans le cycle d’entraînement. Concrètement, il faut exécuter des jeux de contrôle synthétiques, des campagnes de red team et des attaques d’extraction simulées avant toute mise en production. Ces exercices fournissent des métriques exploitables et permettent d’établir des seuils clairs qui déclenchent des actions correctives.
Déploiement, surveillance et mécanismes de mitigation
Au-delà des tests, le parcours de déploiement doit intégrer des garde-fous techniques qui réduisent la fenêtre d’exposition. Par exemple, des déploiements canary avec surveillance fine des sorties, des quotas limités et des filtres de sécurité sur les réponses aident à détecter des comportements révélateurs de fragments d’entraînement. La surveillance continue doit corréler logs d’accès, versions de modèles et jeux de données. Ainsi, on peut isoler rapidement un incident sans interrompre l’ensemble des services. Enfin, la gouvernance opérationnelle transforme les résultats techniques en décisions acceptables pour l’entreprise. Documenter les responsabilités, formaliser les critères d’acceptation et prévoir des revues périodiques permet d’arbitrer entre performance et sécurité. La budgétisation des efforts de sécurité, la revue des contrats fournisseurs et l’intégration de contrôles automatisés dans les pipelines garantissent un niveau de protection conforme aux exigences métier et réglementaires.
Pipelines reproductibles et audits
Au‑delà des techniques cryptographiques, mettre en place un pipeline reproductible et auditable est une clé pour limiter les risques. Peut-on entraîner une IA sur ses propres données en toute sécurité passe par l’automatisation de la préparation des données. Il faut aussi enregistrer de façon immuable les versions de jeux de données et des modèles. L’intégration de contrôles automatisés qui valident la conformité des données avant chaque entraînement réduit les erreurs humaines. Ainsi, on peut tracer précisément l’origine d’un problème. Un levier très concret est l’introduction de jeux de tests anonymes et d’examens adversariaux systématiques. Synthétiser des datasets de contrôle, exécuter des attaques d’extraction en environnement clos et comparer les résultats à des seuils de tolérance permet d’objectiver le niveau de fuite potentiel. Dans ce cadre, les décisions de mise en production se basent sur des preuves issues de tests plutôt que sur des impressions.
Anonymisation, pseudonymisation et risques de ré-identification
L’anonymisation ne se limite pas à supprimer les noms et identifiants. Les quasi‑identifiants peuvent permettre une ré‑identification via des recoupements. Les approches classiques comme la pseudonymisation et le masquage doivent être complétées par des évaluations de risque de ré‑identification. Selon le cas d’usage, des techniques formelles comme la differential privacy sont nécessaires. Cette dernière offre des garanties mathématiques contre l’extraction d’exemples. En revanche, elle requiert une conception attentive des budgets de confidentialité et peut impacter la qualité des modèles.
Chiffrement des données et gestion des accès
Sur le plan opérationnel, la gestion des clefs et le chiffrement côté serveur ou côté client sont cruciaux. Le chiffrement protège les données au repos et en transit. Il faut cependant associer des politiques de rotation des clefs, des contrôles d’accès basés sur les rôles et des environnements d’exécution isolés. Ces mesures limitent les risques liés aux erreurs humaines ou aux compromissions internes. En fonction des contraintes de performance, on peut combiner chiffrement, enclaves sécurisées et méthodes de calcul privacy‑preserving pour réduire la centralisation des données sensibles.
Tests de ré-identification et audits indépendants
Pour valider l’efficacité des mesures d’anonymisation, les équipes doivent exécuter des tests de ré-identification et mener des audits indépendants.. Ces évaluations estiment les taux de succès d’attaques réalistes et aident à ajuster la minimisation et la suppression de champs. La traçabilité des transformations appliquées aux jeux de données et la conservation de jeux de test anonymes facilitent ces audits. Elles renforcent la confiance des parties prenantes sans empêcher l’innovation avec les données internes.
Limites du chiffrement et approche combinée
Le chiffrement protège les données mais n’empêche pas toujours les fuites via le modèle ; il reste cependant essentiel pour réduire les accès non autorisés. L’anonymisation et la pseudonymisation pré‑traitent les jeux de données pour éliminer ou masquer les identifiants directs et réduire la ré‑identification lors d’attaques postérieures. Pour des scénarios pratiques, combiner chiffrement et techniques de masquage diminue significativement l’exposition. Il est important d’évaluer régulièrement l’efficacité des méthodes d’anonymisation et de renouveler clés et politiques d’accès selon le cycle de vie des données. Le recours au chiffrement côté client comme complément est une option à considérer dans des contextes sensibles.
Concrètement, entraîner une IA sur ses propres données en toute sécurité repose sur une combinaison cohérente de chiffrement, de contrôle des accès, de tests de fuite et de gouvernance, et non sur un mécanisme isolé ou une promesse technologique.
FAQ
Quelles sont les premières mesures à prendre ?
Isoler l’environnement d’entraînement, chiffrer les jeux de données et restreindre les accès par rôles sont des prérequis.
L’anonymisation suffit-elle ?
L’anonymisation réduit le risque, mais elle n’offre pas une protection totale, il faut la combiner avec d’autres mesures comme la minimisation des données et la surveillance continue.
Peut-on utiliser l’apprentissage fédéré en entreprise ?
Oui, l’apprentissage fédéré convient lorsque les organisations conservent les données distribuées et ne peuvent pas les centraliser pour des raisons réglementaires ou de confidentialité.
Quels audits réaliser avant déploiement ?
Audits de sécurité des accès, tests de fuite via extraction et revue des pipelines de données sont essentiels avant toute mise en production.
Faut-il documenter chaque jeu de données ?
La traçabilité et la documentation des jeux de données permettent de répondre rapidement en cas d’incident et facilitent la conformité.
Peut-on entraîner une IA sur des données personnelles au sens du RGPD ?
Oui, mais uniquement si les principes de minimisation, de finalité et de sécurité sont respectés. Dans la majorité des cas, une anonymisation robuste ou des techniques de privacy-preserving sont nécessaires pour rester conforme.





